







开云体育 
开云体育官方开源22万条DeepSeek R1的高质量数据!你也能复现DpSk了
 2026-02-03
2026-02-03 浏览次数:
次
浏览次数:
次 返回列表
返回列表开云体育[永久网址:363050.com]成立于2022年在中国,是华人市场最大的线上娱乐服务供应商而且是亚洲最大的在线娱乐博彩公司之一。包括开云、开云棋牌、开云彩票、开云电竞、开云电子、全球各地赛事、动画直播、视频直播等服务。开云体育,开云体育官方,开云app下载,开云体育靠谱吗,开云官网,欢迎注册体验!当中国大模型撕开硅谷的防线之后,在预设中总是落后半拍的中国 AI 军团,这次竟完成了一次反向技术输出,引发了全球范围内复现 DeepSeek 的热潮。
DeepSeek-R1 虽然开源,但也没有完全开源,训练数据、训练脚本等关键信息并未完全公布。
不过,有技术报告,相当于拥有着复现 R1 的指导方针,已经有不少执行力强的团队用小模型见证「aha moment」了。在浩浩荡荡的复刻大军中,最令人瞩目的,当数 Hugging Face 领衔的 Open R1 项目。
Open R1 宣称要做到完全开放复现 DeepSeek-R1,补齐 DeepSeek 所有未公开的技术细节。Open R1 项目刚刚启动不过几周,他们已经完成了:
在开源社区的众志成城,Open R1 更是动作迅速。今天,他们发布了 OpenR1-Math-220k 数据集,又补全了一块 DeepSeek R1「碎片」—— 合成数据。
DeepSeek R1 的一个重要优势在于它能够将高级推理能力迁移到较小的模型中。DeepSeek 团队生成了 60 万条推理数据,在 Qwen 和 Llama 等开源模型上证明了这种迁移能力。即使不使用强化学习,直接从 R1 模型进行迁移也能实现强大的推理性能。
然而,这些合成数据仅 DeepSeek 可见,未对其他团队开放阅读权限。
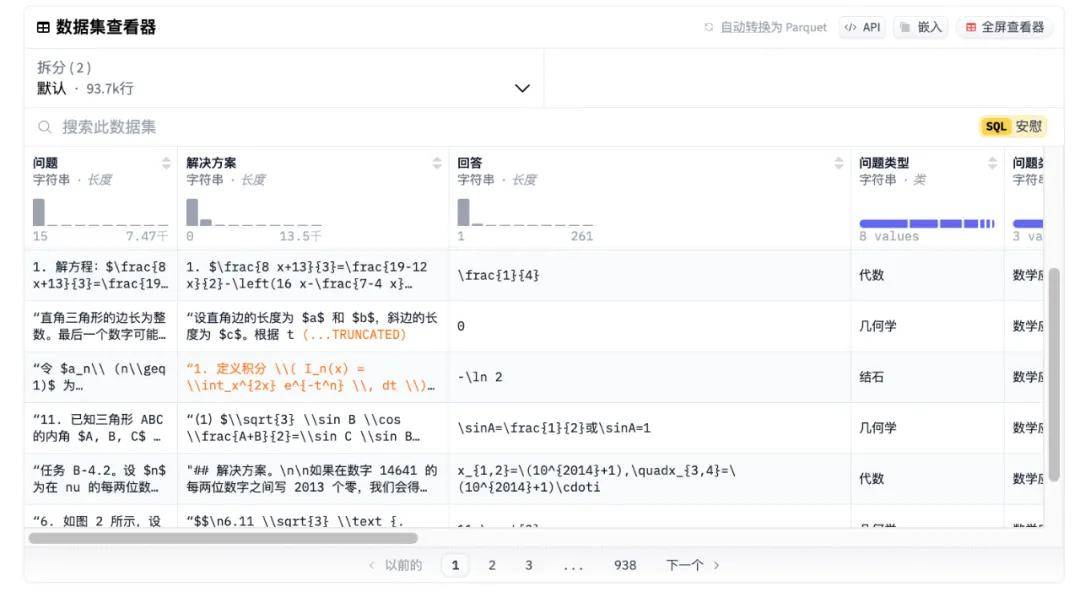
OpenR1-Math-220k 数据集就是来补上这块空缺的。具体而言,Open R1 团队使用 DeepSeek R1 生成了 80 万条推理轨迹,经过筛选和验证后得到了 22 万条高质量数据。
下面就让我们来看看 OpenR1-Math-220k 数据集的特点,以及它是怎么诞生的:
然而,为了进行推理公众公开发布,这促使社区独立重建类似的数据集。另外,社区已经发布了多个开放数据集,包括 OpenThoughts-114k、Bespoke-Stratos-17k、Dolphin-R1 和 LIMO。
default(94k 问题):这部分数据在经过监督微调(SFT)后表现最佳。
extended(131k 问题):这部分数据包含额外的 NuminaMath 1.5 数据源,例如 cn_k12,提供了更多的推理公式。(研究发现这个子集在经过监督微调后的性能低于默认数据集,可能是因为 cn_k12 中的问题相对简单。)
Open R1 团队表示,希望这个可扩展的、高质量的推理数据生成过程,能够启发代码生成等数学之外的领域。
为了构建数据集,OpenR1 团队让 DeepSeek R1 为来自 NuminaMath 1.5 的 40 万个问题生成答案。他们遵循了 DeepSeek 技术报告中推荐的参数设置,并在提示词前添加了以下指令:
为了确保生成过程的高效性,团队将每次生成的 tokens 限制设置为 16k。经过分析发现,只有 75% 的问题能够在 8k tokens 内解决,而大多数剩余问题需要完整的 16k tokens。
最初,他们使用 vLLM 进行推理,每个 H100 节点每秒可以生成 15 个答案,并且相关生成脚本已分享在 OpenR1 仓库中。最近,他们又开始尝试使用 SGLang,每个 H100 节点每秒可以生成 25 个答案(速度提升了近两倍),这使得 512 个 H100 节点上每天能生成 30 万个问题的答案。
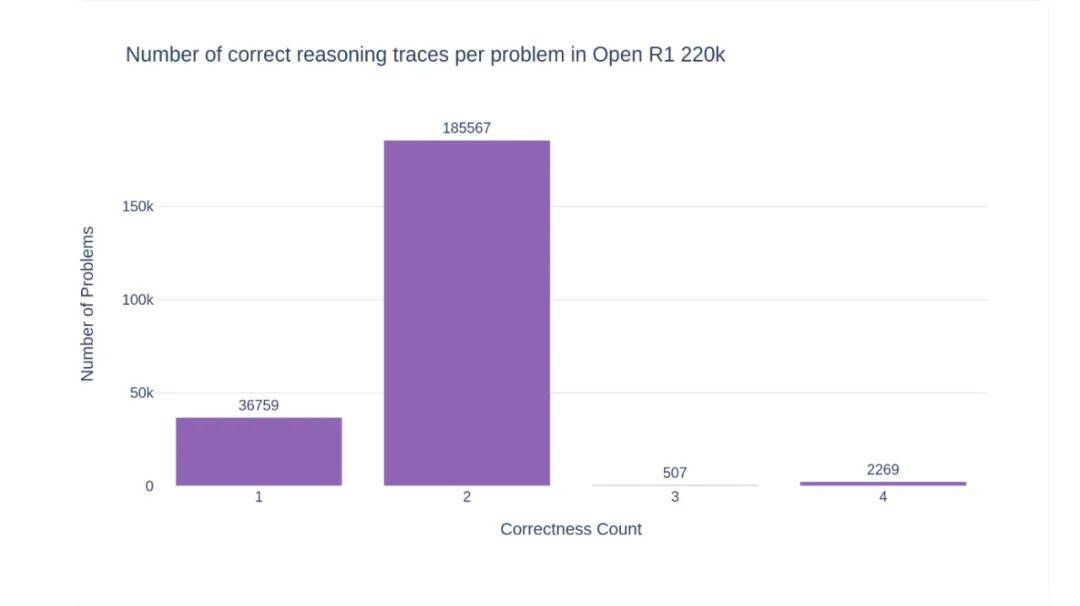
为了在后续的过滤和优化过程中提供更大的灵活性,团队为每个问题生成了两个答案 —— 有时甚至生成四个。这样一来,不仅复刻出了类似于 DeepSeek R1 允许进行拒绝采样的方法,还能使数据集能够适用于如 DPO 等偏好优化方法。
为了确保数据集中只包含高质量且正确的推理结果,Open R1 团队设计了一套数学验证系统,用于自动比对 LLM 生成的复杂数学表达式答案与数据集中的标准答案。
在这个过程中,OpenR1 团队发现大约 55% 的问题至少有一个正确答案。然而,NuminaMath 1.5 数据集中有很多答案是空的,或者格式不符合验证标准,这都给自动验证带来了困难。
为了解决这些问题,Open R1 团队先是对 Math-Verify 工具进行了改进,使其能够处理更多不常见的答案格式,再使用 Llama-3.3-70B-Instruct 模型进行二次评估。
具体来说,对于那些被 Math-Verify 判定为错误的答案,使用 Llama-3.3-70B-Instruct 模型重新评估,识别实际上正确但因格式问题被错判的答案。最终,他们找回了 2.5 万条被「误判」的数据。
优化 Math-Verify 工具:对 Math-Verify 工具进行了改进,使其能够处理更多不常见的答案格式。
对于那些包含多个正确答案的数据行,团队尝试使用奖励模型(RM)作为最终筛选器来选择最佳答案。具体操作如下:
首先,从每个包含多个正确答案的数据行中,去掉(think…/think),提取最终答案;第二,将问题和提取的答案输入到配置了 vLLM 的 Qwen/Qwen2.5-Math-RM-72B 模型中,获取每个答案的评分;接着,根据模型评分,对每个包含多个正确答案的数据行排名,选择排名最高的答案纳入训练数据集。
遗憾的是,消融实验表明,这种方法并没有比随机选择一个正确答案带来更好的模型性能。Open R1 团队的判断是,可能在使用奖励模型评分时,不仅要考虑最终答案,还要包括推理过程。
为了将上下文长度从 4k 扩展到 32k,他们将 RoPE 频率提高到 300k。训练遵循线性学习率调度,其中包含 10% 的预热阶段。
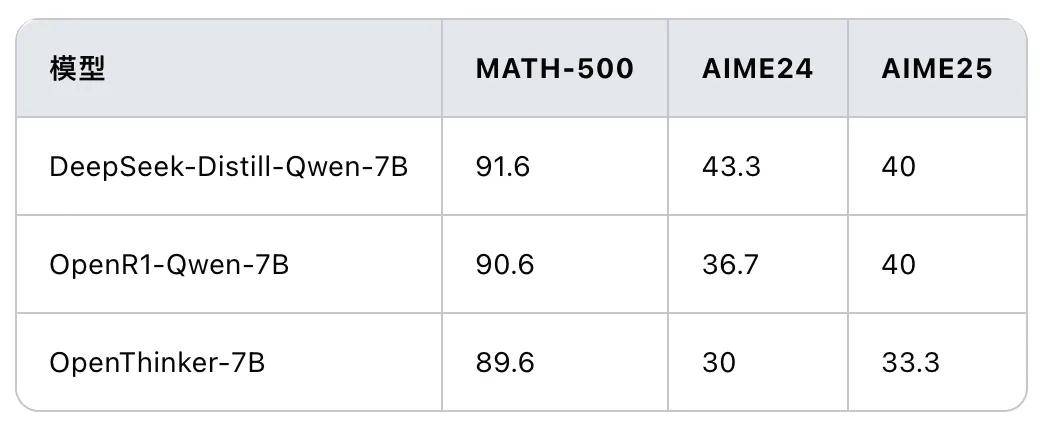
本周 AIME 2025 开赛,来自苏黎世联邦理工学院的研究人员用新题来测评了多款模型,却发现各种模型的数学能力下降了 10-20 个百分点之间。有研究者发现这些「全新」的 AIME 题可能已经在互联网论坛泄露,这有可能造成意外的过拟合问题,这也凸显了新鲜测试数据的困境。
同时,开源社区也从多个角度探索了 GRPO,有多个研究实验室表明,大约 1000 个高质量的训练样本可能就足以在现有的开源模型中引发推理能力。

马里兰大学的一篇论文表明,通过使用循环语言模型,可以在潜在空间中隐式推理,从而在测试时扩展计算能力,这类似于 Meta 的 Coconut。这些方法的优势在于它们的计算效率更高:通过探索潜在空间,无需生成大量「思考」token 即可获得高性能。
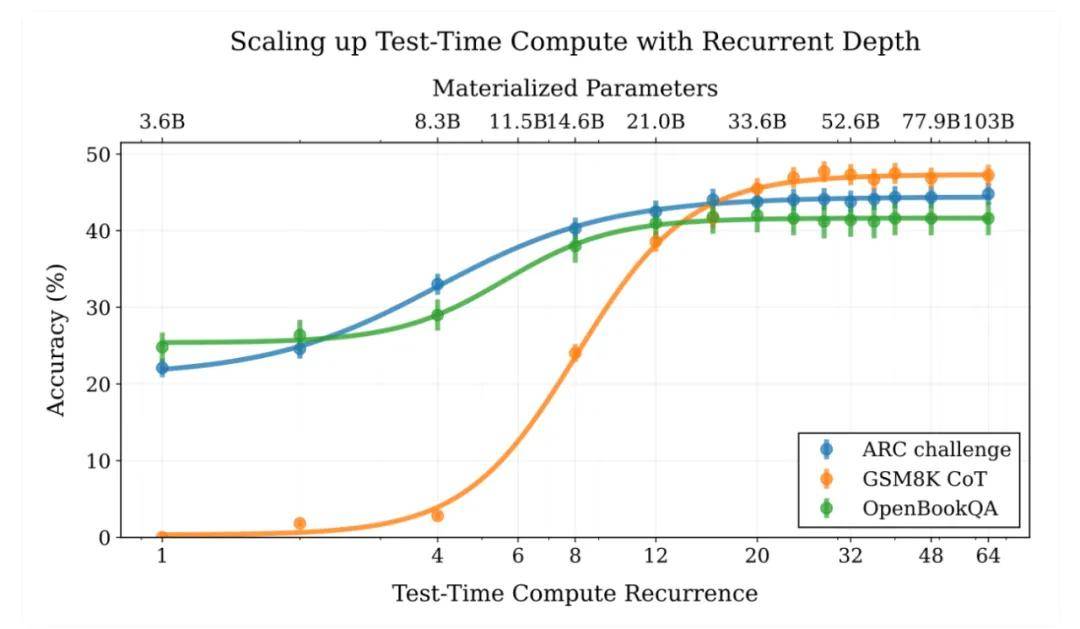
尽管 DeepSeek R1 使用了 600k 推理轨迹进行蒸馏,但最新研究表明,复杂的推理能力并非单纯通过大规模训练在语言模型中实现,而是可以通过少量精心设计的样本达成。
s1K 数据集就是一个很好的例子。它包含 1000 个经过精心挑选的数学问题,以及从 Gemini Flash 蒸馏出的推理轨迹。在选择问题时,研究者注重难度、多样性和质量。通过在 s1K 数据集上对 Qwen2.5-32B-Instruct 进行微调,研究者成功使其在竞赛数学基准测试中超过了 OpenAI 的 o1-preview,最高提升了 27%。
另一个数据集 LIMO 也进一步验证了这一理念。它仅使用 817 个训练样本,就在 AIME 和 MATH 基准测试中取得了出色的表现。LIMO 的作者推测,当模型在预训练阶段已经积累了丰富的知识后,可能只需要少量结构良好的样本,就能解锁高级推理能力。
Qwen2.5-32B-Instruct 模型在 s1K 数据集上微调后表现出色,其中一个关键因素是采用了「预算强制」。这是一种测试时的计算技术,通过在模型生成中添加「等待」token 来延长推理时间,或者添加「结束思考」的 token 来截断推理。
这种方法使研究者能够灵活调整模型的思考时间,并发现随着思考时间的增加,模型在不同数学基准测试中的准确性也随之提高。
同样,Yeo 等人在研究《Demystifying Long Chain-of-Thought Reasoning in LLMs》中探讨了思维链(CoT)长度对模型性能的影响。他们引入了一种名为「余弦奖励」的新奖励函数,用于在正确生成时激励较短的 CoT,在错误生成时激励较长的 CoT。这种奖励机制在模型的最大上下文大小有限且平均响应长度可能失控的情况下,能够稳定强化学习训练。

此外,当模型在处理难题时出现奖励劫持的迹象(即通过重复而非真正解决问题来增加 CoT 长度),研究者还会采用重复惩罚机制,以避免模型陷入无效的循环推理。
Open R1 团队表示,现在 GRPO 已经在 TRL 中顺利运行,他们正在开展一系列广泛的实验,以了解哪些超参数和奖励函数对训练的影响最大。
